Data Analytics Services and Infrastructure
Data Analytics Services
We provide our research community with the latest rapidly evolving methodologies through the following services:
- Data collection: Gather data relevant to the research hypothesis from various sources, including clinical systems (EMR, PACS, Genomics, etc.), experiments, surveys, observations, or consortia/public data sources.
- Data Cleaning and Preprocessing (Data Wrangling): Raw data often needs cleaning and preprocessing to handle missing values, outliers, and inconsistencies. This step ensures that the data is ready for analysis and interpretation.
- Exploratory Data Analysis (EDA): We use statistical and visualization techniques to explore the characteristics of the data. EDA helps in uncovering patterns, trends, and relationships within the data.
- Hypothesis Testing: Use of statistical methods to test their validity. We help in conducting rigorous statistical tests to draw meaningful conclusions.
- Data Visualization and Communication: Visualization techniques are used to present research findings transparently and interpretably. Effective communication of results is essential for sharing insights with the research community and beyond.
- Reproducibility and Transparency: We emphasize reproducibility, ensuring that others can replicate analyses and results. Transparent reporting of methods and data processing steps is critical for the scientific community's trust.
- Interdisciplinary Collaboration: We collaborate with subject-matter experts from various fields to ensure that the analysis aligns with the research context. Collaborative efforts contribute to a more comprehensive understanding of complex phenomena.
- Ethical Considerations: Ethical considerations are paramount in data science for research, especially when dealing with sensitive data or human subjects. Ensuring privacy, informed consent, and responsible data handling are integral to the research process.
Artificial Intelligence and Machine Learning
Artificial Intelligence (AI) is increasingly playing a significant role in research across various basic and clinical disciplines, providing advanced tools and techniques to analyze complex data, identify patterns, and make predictions. AI in research is continually evolving, and its integration is transforming the way researchers approach complex problems, providing new perspectives and capabilities that were not possible with traditional methods. Ethical considerations, transparency, and interdisciplinary collaboration are essential elements in ensuring the responsible and effective use of AI in research. Our team provides:
- Automated Data Analysis: AI algorithms can automate the analysis of large and complex datasets, enabling researchers to process information more efficiently. Machine learning models can identify trends, correlations, and anomalies in data that might be challenging for traditional analytical methods.
- Predictive Modeling: AI techniques, especially machine learning, are used to build predictive models based on historical medical or biological data. These models can be applied in research scenarios to forecast outcomes, trends, or behaviors, aiding in decision-making from medical records.
- Natural Language Processing (NLP): NLP allows researchers to analyze and extract information from unstructured text data such as research papers, articles, and clinical notes. NLP is commonly applied for summarization and information retrieval from medical records and doctor's notes. We use traditional and the latest Gen-AI methodologies (e.g., LLMs and transformers) for content/semantic NLP.
- Image and Pattern Recognition: AI, particularly computer vision, is applied in subspecialties like Radiology, Pathology, and other diagnostic fields and primary research, e.g., cell imaging, for image and pattern recognition, classification, and subsequent quantification. It assists in tasks such as identifying structures in medical images or analyzing microscopic patterns using deep learning or transformer neural networks.
- Time Series Analysis: We use statistical methods and AI models to analyze time-ordered data points, e.g., EEG, vital signs, etc. The analysis aims to understand the temporal patterns, trends, and behaviors within the data.
- Personalized Medicine: AI contributes to the field of personalized medicine by analyzing individual patient data to tailor treatments based on genetic, clinical, and lifestyle factors. Predictive analytics help identify patient-specific risks and responses to treatments.
- Optimization and Simulation: AI optimization algorithms are used to find optimal solutions in complex research scenarios, such as experimental design or resource allocation. Simulation models powered by AI help researchers understand and predict the behavior of complex systems.
- Collaborative Filtering: Recommender systems, a type of AI application, help researchers discover relevant publications, collaborators, or research articles based on their interests and preferences.
- Ethical Considerations and Bias Mitigation: AI in research includes considerations of ethical use and potential biases in algorithms. Researchers work on developing and implementing strategies to ensure fairness, transparency, and accountability in AI applications.
Data Analytics Infrastructure
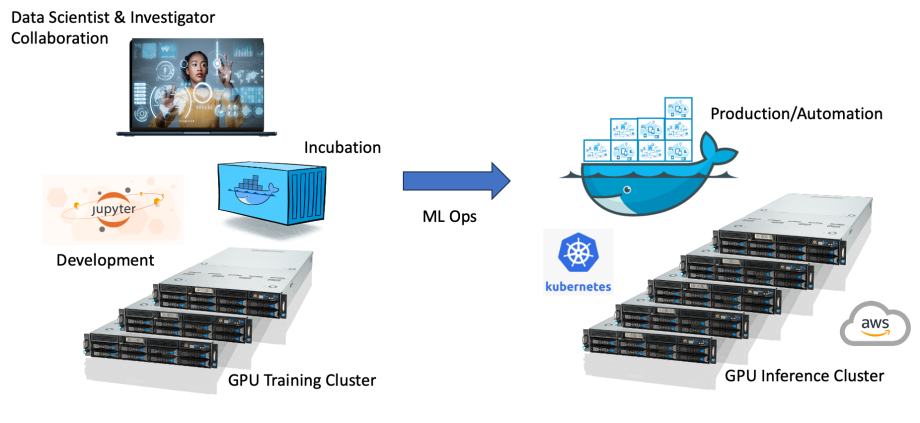
The Data Science Cluster (DSC) serves as a robust High-Performance Computing (HPC) resource dedicated to advancing data science initiatives at The Saban Research Institute (TSRI). Comprising both AI/ML model training nodes (3 nodes with 4 GPUs each) and inference nodes (15 nodes with 1 GPU each), the cluster boasts substantial computing power. Each node is fortified with 1TB of RAM and 24TB of SAS storage. To facilitate seamless data access and sharing, all storage is integrated into a CEPH distributed filesystem and interconnected via a high-speed 100Gbit/s fiber network linking the nodes.
Access to the DSC is streamlined through the utilization of Docker containers, encapsulating project-specific data analytics and AI/ML programs. Employing Kubernetes for orchestration, the runtime environment of these Docker containers is efficiently managed to ensure optimal performance.
The Data Science Team is responsible for operating and maintaining the DSC and overseeing the Docker environment. Should you wish to create and deploy your own project Docker container on the DSC, please contact us for guidance and assistance.
We are committed to supporting and facilitating your data science endeavors on the DSC, and we look forward to collaborating with you to unleash the full potential of your projects.